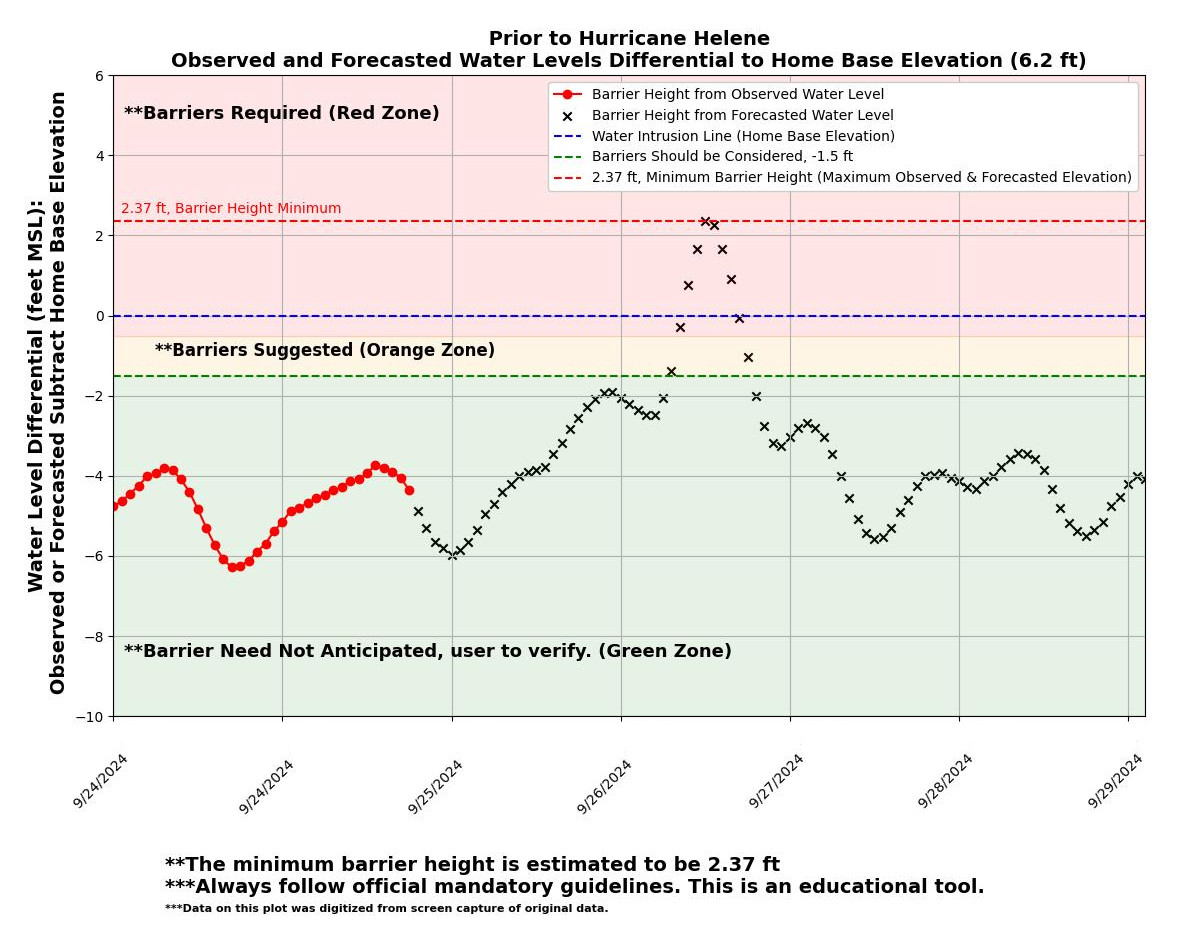
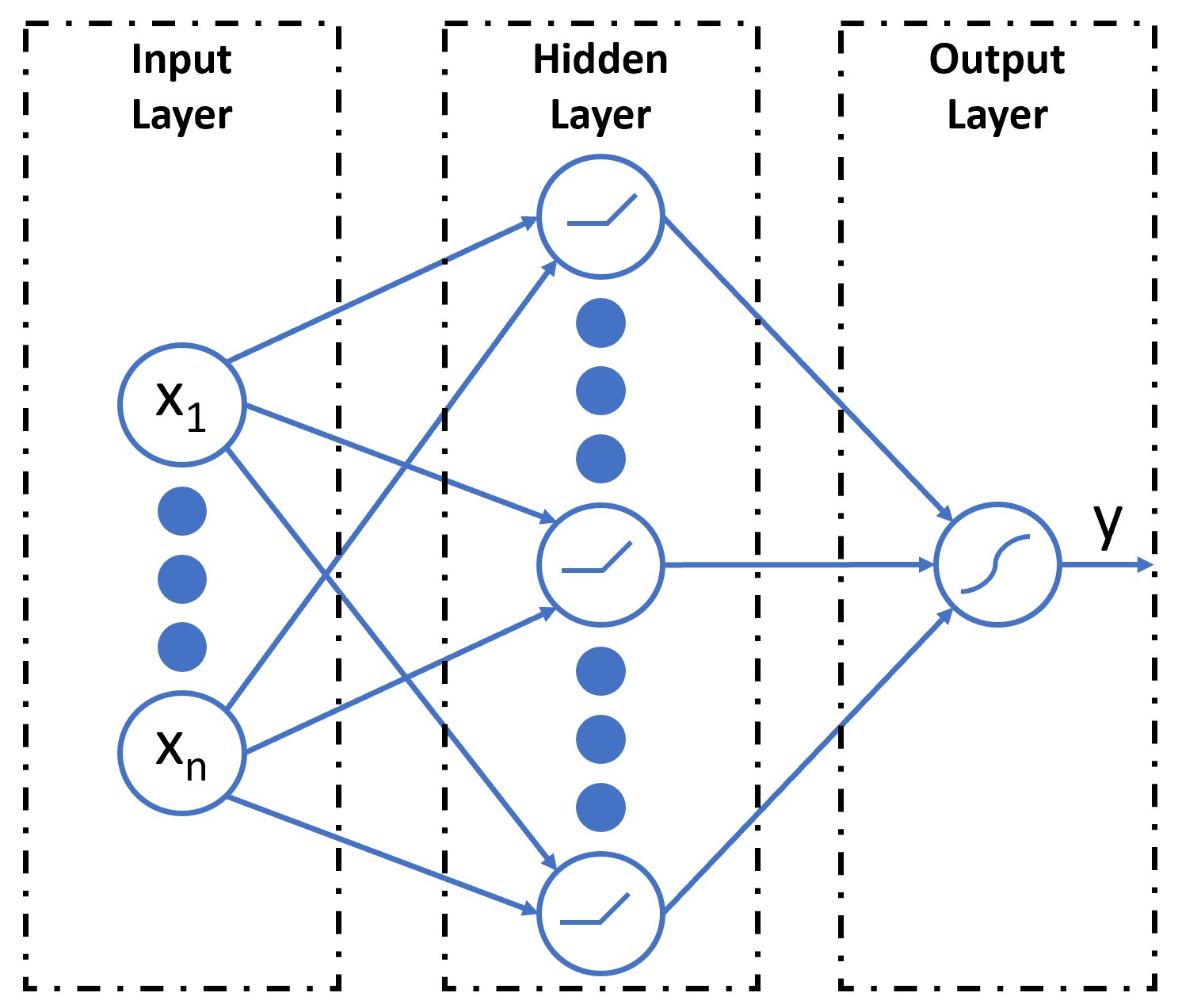
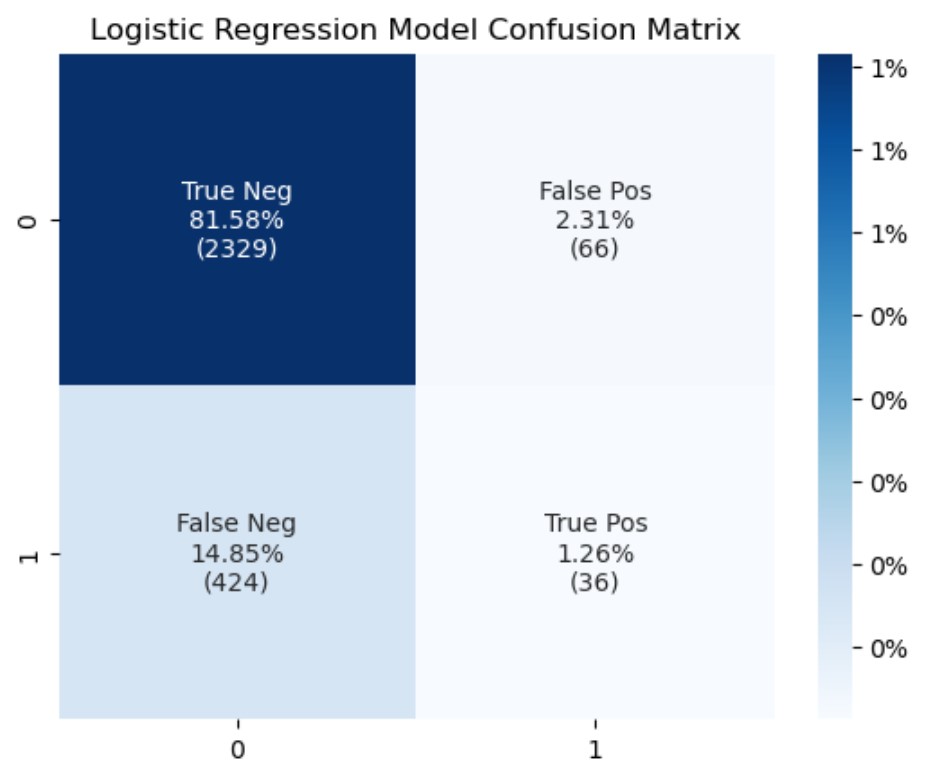
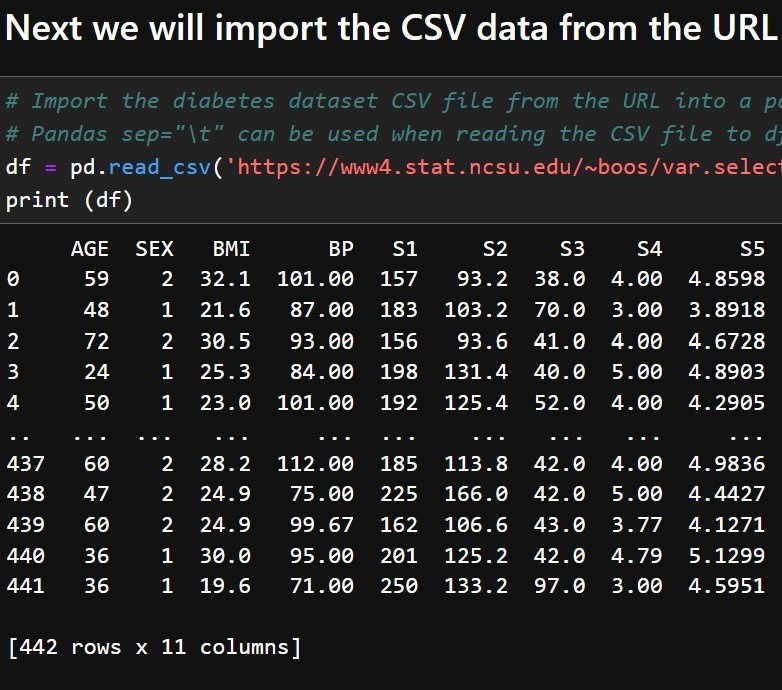
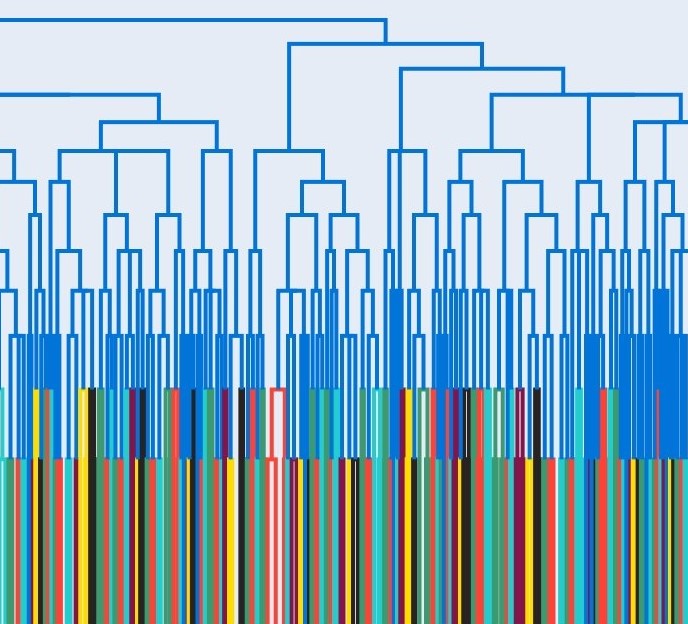
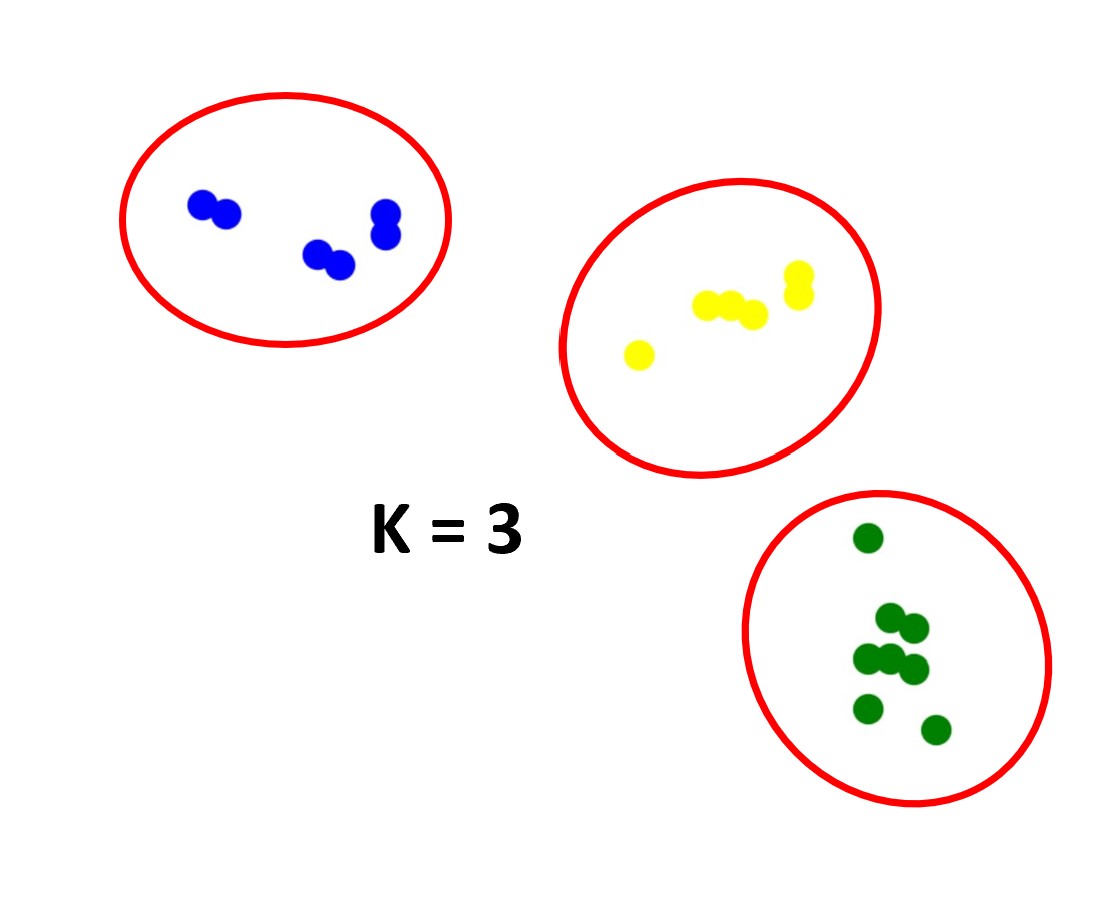
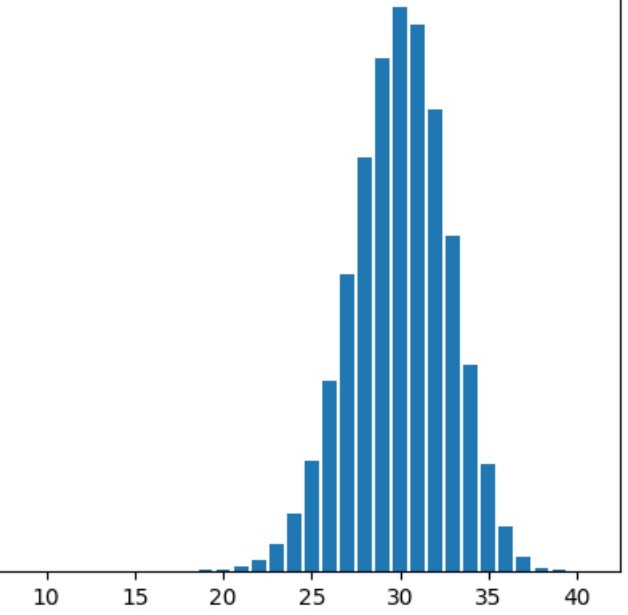
Welcome to my portfolio! I am continuing to add exciting personal projects that I work on in my spare time. I have been 1.5 miles underground vertically into the earth and guess what I found? Data, data, and more data! Most of my career as an engineer has been spent working under confidentiality agreements. I am a registered Professional Engineer (NC, FL, and LA) and data scientist with 11+ years of demonstrated success utilizing a diverse set of software suites and technologies to design, implement, and analyze operational and engineering data in mining, civil, and environmental applications.
Want to Collab? Great! I have a strong background of research, production, engineering, consulting, and customer service which enables me to analyze complex problems, develop and implement solutions, evaluate the process with measurable parameters, develop content, and present findings to all technical levels. Let's get the job done.