Analyzing Diabetes with XGBoost
- The objective of this project is to analyze a diabetes dataset utilizing XGBoost in a python jupyter notebook.
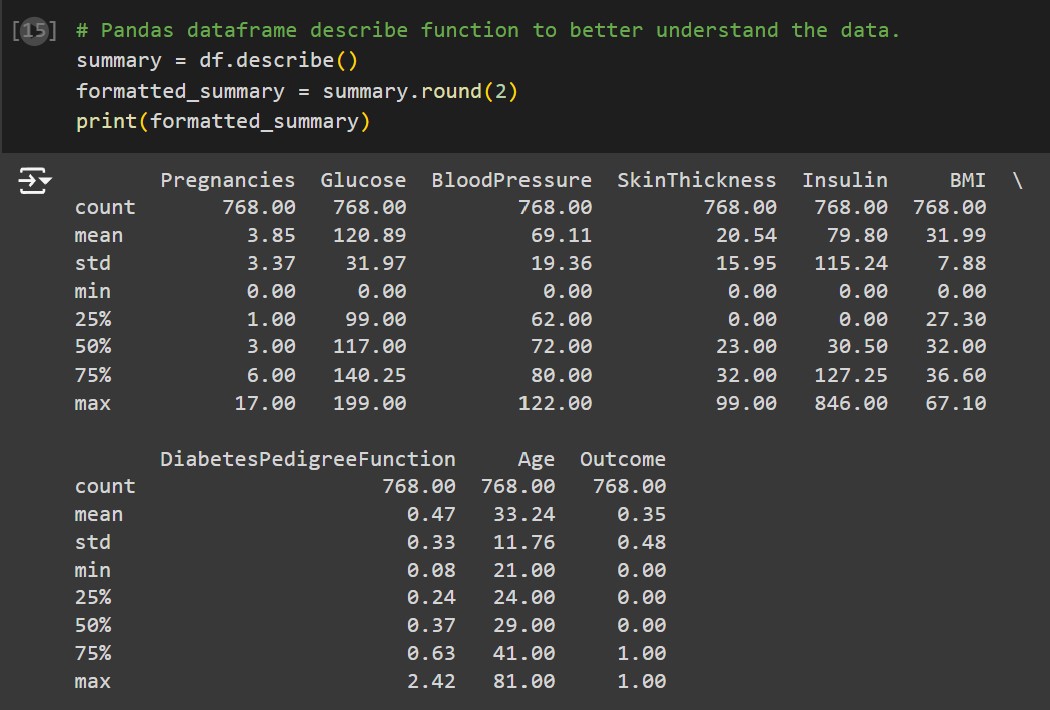
- This diabetes dataset contains the variables pregnancies, glucose, blood pressure, skin thickness, insulin, BMI, diabetes pedigree function, age, and outcome (binary- positive or negative).
- XGBoost is an optimized distributed gradient boosting library that can be used to implement machine learning algorithms under the gradient boosting framework. More information can be found here: XGboost.ReadtheDocs.io
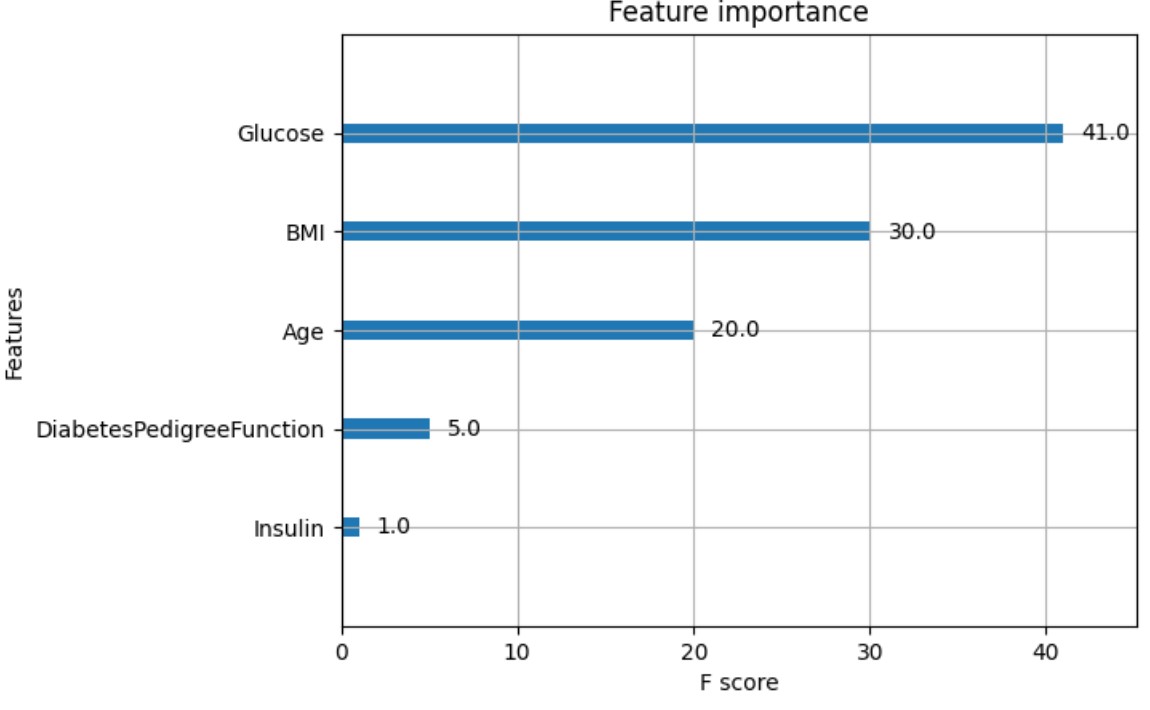
- Tables and Graphs can be found here: